
LiLz株式会社(以下、リルズ)と東北大学大学院情報科学研究科の大関真之教授らの研究グループが、AI開発で大きな課題だった「間違ったラベルの付いたデータ」(ラベルノイズ)を効率的に取り除く新しい技術を開発したことを発表しました。この技術は、AIの「汎化性能」、つまりまだ見たことのないデータに対しても正確に判断できる能力を大きく改善すると期待されています。
AIの学習データに残る「間違い」が大きな課題
これまでのAI開発では、AIに学習させるデータの中に「間違った情報」が混ざっていると、AIの性能が下がってしまう問題がありました。例えば、犬の画像に誤って「猫」というラベルが付いているようなケースです。このような「間違った情報」を取り除く作業は、人間の手で行うことが多く、近年のAI開発で用いられるデータ量は非常に大規模になる傾向があるため、膨大な時間と手間がかかる大きな課題でした。
量子アニーリングでデータ浄化を高速化
今回開発された技術は、「ブラックボックス最適化」と「量子アニーリング」という二つの技術を組み合わせたものです。これにより、AIが学習するデータの中から、間違ったラベルが付いている可能性の高いデータを効率的に見つけ出し、取り除くことが可能になりました。
特に、多くのデータの組み合わせの中から最適なものを選ぶという、これまで非常に難しかった作業を量子アニーリングが高速に実行できる点が大きな特徴です。この技術を使うことで、AIの学習に悪い影響を与えるデータが優先的に取り除かれることが実験で確認されています。
さらに、D-Wave Quantum社の量子アニーラーという特別な計算機を使うと、従来のコンピューターに比べて、データの浄化作業が約10倍から100倍も速くなることが分かりました。
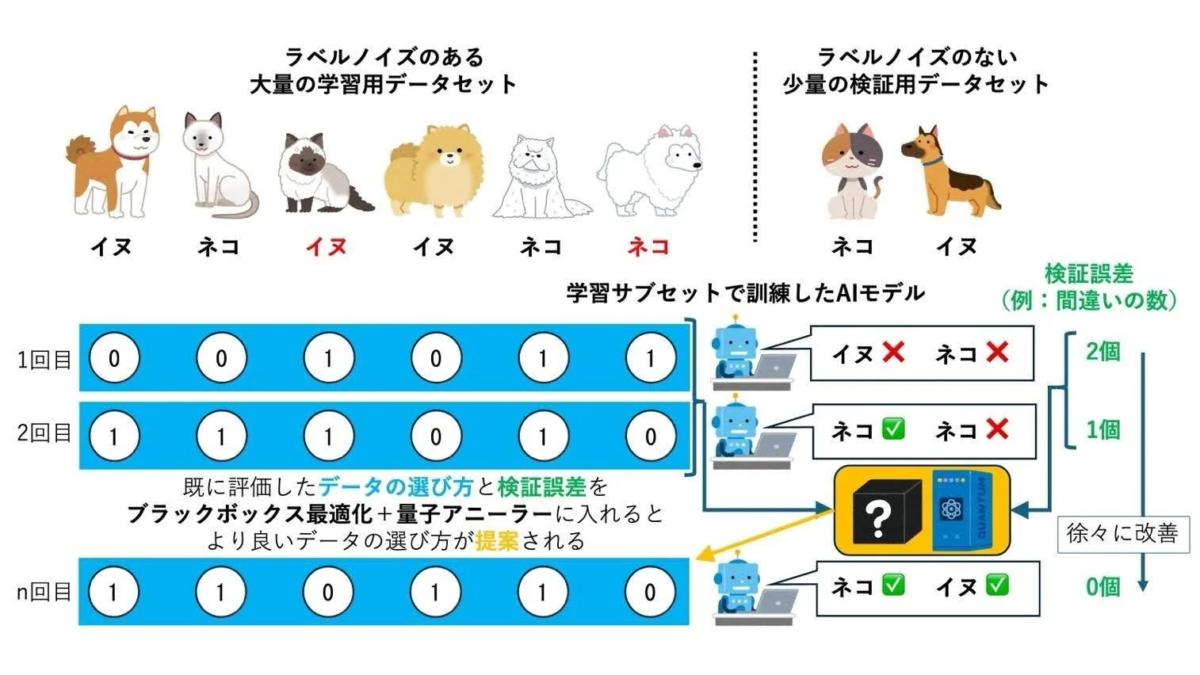
図1:提案手法の概念図
図1では、この技術の考え方が示されています。まず、少しだけ正しい情報が分かっている検証用のデータを用意し、それを使ってAIの学習データから間違った情報を取り除く方法を探していきます。量子アニーラーを使うことで、この「データの選び方」をより速く、より良く見つけ出すことができるのです。
今後の展開と期待
この新しい技術は、これから様々な分野で活用されることが期待されています。特に、たくさんのデータを扱う産業や医療の現場で、データの質を高めることに役立つでしょう。
また、ラベルが付いていないデータの品質を向上させたり、AIが学習するデータと注目する特徴を同時に最適化したりする応用も考えられます。
リルズは、「機械学習とIoTの技術融合で、現場の仕事をラクにする」というミッションを実現すべく、今後も学術機関との共同研究などを通じて、様々な産業の現場課題を解決していくとしています。
本研究の主なポイント
-
AI開発の大きな課題である「間違ったラベルの付いたデータ」を効率的に取り除く新しい方法を開発しました。
-
「ブラックボックス最適化」と「量子アニーリング」を組み合わせることで、これまで難しかった「検証誤差の直接最適化」を実現しました。
-
D-Wave Quantum社の量子アニーラーを使うことで、従来のコンピューターに比べて処理速度が10倍から100倍に高速化されることが確認されました。
-
この研究成果は、大規模な実データを扱う医療や産業分野への応用が期待されています。
関連情報
-
YouTube解説動画(日本語版):https://youtu.be/YI9J9BVDY0o
-
YouTube解説動画(英語版):https://youtu.be/acWqba1lleg
-
論文情報:
-
タイトル:Filtering out mislabeled training instances using black-box optimization and quantum annealing
-
著者:Makoto Otsuka*, Kento Kodama, Keisuke Morita, Masayuki Ohzeki
-
掲載誌:Scientific Reports
-
-
東北大学大学院情報科学研究科 大関真之教授:https://altema.is.tohoku.ac.jp/~mohzeki/
-
東北大学 プレスリリース:https://www.tohoku.ac.jp/japanese/2025/10/press20251031-02-quantum.html
-
東北大学 公式X:https://x.com/tohoku_univ/status/1984130629127360661
-
LiLz株式会社(公式HP):https://lilz.jp/
-
LiLz株式会社(チーム紹介note):https://note.com/lilz/

