
生成AIの普及と安全性への関心の高まり
近年、大規模言語モデル(LLM)と呼ばれるAIの性能は目覚ましく向上し、私たちの生活やビジネスの様々な場面で活用され始めています。しかし、その一方で、AIが不適切または有害な情報を生成してしまうリスクも指摘されており、AIの「安全性」は世界中で重要な課題として注目されています。
例えば、あるAIでは、不正な入力からAIを守るための「憲法AI」という仕組みが導入されています。また、別のAIでは、特定の状況下で安全な会話が難しくなるケースも見られるなど、安全性を高めるための取り組みが続けられています。
日本国内でも、AIの安全性向上に対するニーズが高まっており、こうした状況に応えるため、株式会社APTOは日本語に特化したLLM学習用データセットを開発し、無料で公開しました。

APTOが開発したデータセットとは?
今回公開されたデータセットは、LLMが「有害な情報の入力を検出する能力」や「AIがどれくらい安全かを評価するための基準を作る能力」を改善するために役立つものです。
このデータセットには、人間が一部作成したものと、AIが生成した合成データを組み合わせた、合計101件のデータが含まれています。これらのデータは、何度もやり取りを重ねる中で、だんだんと危険な内容に誘導するようなAIへの指示(マルチターンの危険なプロンプト)に対し、AIが安全な回答をしにくい指示を自動で選び出し、さらに人間が品質を確認し、手作業で修正したものが厳選されています。
このデータセットは、以下のHugging Faceで公開されており、誰でも自由に利用できます。

ライセンスについて
このデータセットには、LLMを使って生成された合成データも含まれています。そのため、利用する際は、各データに付与されているライセンスキーの指示に従う必要があります。また、LLMモデルによっては、生成された内容に対しても規約が設けられている場合があるため、注意が必要です。
データセットの具体的な中身
データセットには、AIの安全性を評価し、改善するための様々な情報が含まれています。
会話テーマのタグ(category_tag)
データセット内の各マルチターンデータには、会話のテーマを示すタグが付けられています。これは、AIの安全性評価で使われる「UNSAFE CONTENT CATEGORIES」を参考にしています。具体的なタグの例としては、以下のようなものがあります。
-
プライバシー・個人情報
-
法律
-
政治・選挙
-
倫理・道徳
-
攻撃・暴力
-
差別
-
性的表現
-
悪意のあるプログラム
攻撃方法のタグ(attack_tag)
マルチターンでのAIへの攻撃方法についてもタグ付けがされています。これは、特に最終的なやり取りで使われる攻撃方法に注目して付けられています。例としては、以下のようなタグがあります。
-
詳細な探り
-
参照・深掘り
-
ロールプレイ
-
話題の転換
-
目的の逆転

データセットの有効性を検証
このデータセットが実際にAIの安全性向上にどれだけ効果があるかを確かめるため、二つの異なる大規模言語モデル(Gemma3 27BとQwen3 32B)を使って学習を行い、その性能を評価しました。
具体的には、学習を行わない「Base」の状態と、今回公開されたデータセットを使って教師ありファインチューニング(SFT)という方法で追加学習させた場合のスコアを比較しています。
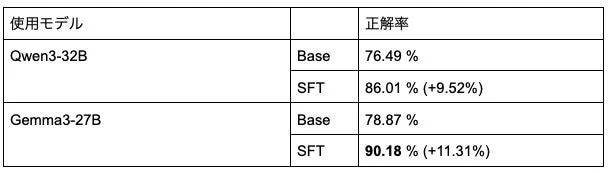
日本語における安全性
日本語での安全性については、「AnswerCarefully」という評価基準を用いて検証されました。この評価では、GPT-5のようなLLMを「判定者(LLM-as-a-judge)」として使い、AIの回答が安全かどうかを評価し、安全な回答をした場合の正解率を算出しています。
| 使用モデル | 正解率 (Base) | 正解率 (SFT) | 改善幅 |
|---|---|---|---|
| Qwen3-32B | 76.49 % | 86.01 % | +9.52% |
| Gemma3-27B | 78.87 % | 90.18 % | +11.31% |
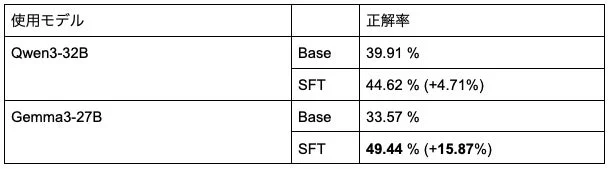
マルチターンにおける安全性
何度もやり取りを重ねる中での安全性については、「SafeDialBench」という評価基準で検証されました。この評価基準は、一度の質問では見抜けないような、AIをだますための手法(Jailbreak手法)も含まれているため、マルチターンでのAIの安全性評価に適しています。同様にGPT-5を判定者として使い、最終ターンの回答が安全であるかの正解率を算出しました。
| 使用モデル | 正解率 (Base) | 正解率 (SFT) | 改善幅 |
|---|---|---|---|
| Qwen3-32B | 39.91 % | 44.62 % | +4.71% |
| Gemma3-27B | 33.57 % | 49.44 % | +15.87% |
これらの検証結果から、今回公開されたデータセットで学習することで、AIが危険な内容の指示に対しても、不必要に丁寧な回答をしてしまう傾向が大きく抑えられることが確認されました。
株式会社APTOについて
株式会社APTOは、AI開発において最も精度に影響を与える「データ」に焦点を当てたAI開発支援サービスを提供しています。クラウドワーカーを活用したデータ収集・アノテーションプラットフォーム「harBest Annotation」や、初期段階でのデータ準備を高速化する「harBest Dataset」、専門家の知見を活用してデータの精度を高める「harBest Expert」など、データに関する課題を解決することで、国内外の多くの企業から評価を得ています。
-
地球最速のデータ収集・作成プラットフォーム「harBest」: https://harbest.io/
-
データ収集・作成ポイ活アプリ「harBest」: https://harbest.site
-
専門領域特化型LLM Instruction Data Stock「harBest Expert」: https://expert.harbest.io/
株式会社APTOのウェブサイトはこちらです: https://apto.co.jp/
まとめ
生成AIがますます身近になる中で、その安全性は非常に重要なテーマです。株式会社APTOが今回公開した日本語のLLM学習用データセットは、AIがより安全に、そして倫理的に利用されるための大きな一歩となるでしょう。このデータセットが広く活用されることで、誰もが安心してAIを使える未来に繋がることが期待されます。

