現代社会では、情報技術やAIの急速な進展により、情報環境が日々大きく変化しています。以前は最適だった選択が、今では「時代遅れで不適切な選択」となってしまうことも少なくありません。
このような「急激に変化する予測しにくい環境」において、人々が互いの行動を参考にしながらどのように意思決定を進めるのか、その仕組みが理論的に明らかにされました。
社会学習とは?
私たち人間を含む多くの動物は、自分以外の個体(他者)から学ぶ「社会学習」を行います。SNSでの投稿や商品のレビュー、先生や先輩からのアドバイス、専門家の意見など、さまざまな社会的情報は、より良い意思決定をするための大切な情報源です。しかし、他者からの影響は、時に環境の変化への対応を難しくし、集団全体が誤った判断をしてしまう「集合愚(しゅうごうぐ)」を引き起こす可能性もあります。
意思決定を左右する2つの社会学習タイプ
これまでの研究では、人が社会学習を行う際の仕組みとして、主に2つの異なるタイプ(アルゴリズム)があると考えられています。
1. 価値形成(VS: Value Shaping)型
このタイプの人々は、多くの人が選んだ「人気の選択肢」を、本当に価値の高い選択肢だと評価します。例えば、人気のレストランの料理を「美味しいに違いない」と感じるような評価の仕方です。このVS型は、安定した環境では優れた選択肢に素早く集中できるという強みがあります。しかし、環境が急激に変化すると、過去の人気に囚われてしまい、時代遅れの選択肢を選び続けてしまう弱点があります。
2. 決定バイアス(DB: Decision Biasing)型
DB型の人々は、人気の選択肢を選びやすい傾向がある一方で、その選択肢の価値は、人気に左右されず、自分の実際の経験に基づいて評価します。例えば、人気のレストランに出かけることはあっても、料理の味は「自分の舌」で判断する、といった評価の仕方です。このDB型は、安定した環境での効率性はVS型に劣りますが、急激な環境変化に対しても柔軟に対応し、過去の選択に囚われにくいという特性を持っています。

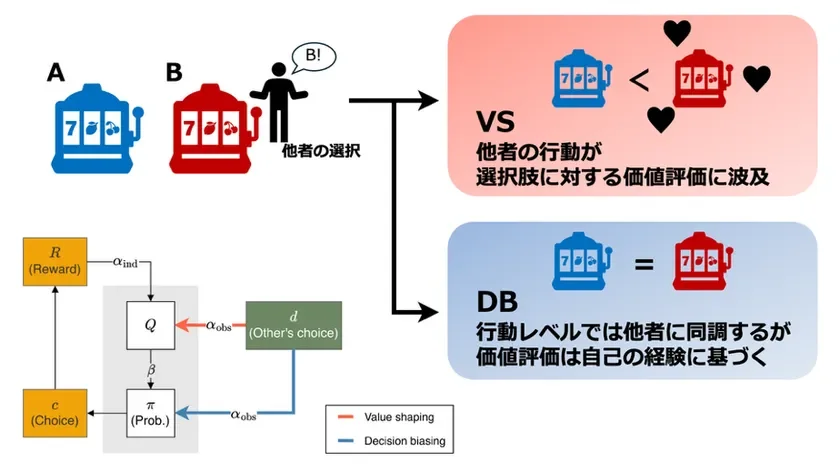
図1 2つの社会学習アルゴリズムの違い。価値形成(VS)型のアルゴリズムでは他者の行動が選択肢に対する価値評価に直接的に波及するのに対して、決定バイアス(DB)型では価値評価はあくまでも自己の報酬経験に基づきます。
研究で明らかになった「集団の知恵」
明治学院大学、東京大学大学院、総合研究大学院大学の研究グループは、これらの2つの社会学習タイプを持つ人々が集団でどのように意思決定を行うかを、コンピューターシミュレーションを使って調べました。
その結果、VS型の人々だけの集団は、安定した環境では良い選択肢に素早くたどり着けますが、環境が急に変わると過去の選択に固執してしまい、判断が遅れてしまうことがわかりました。一方、DB型の人々だけの集団は、安定した環境での意思決定の速さは劣るものの、急な変化にも柔軟に対応できることが示されました。
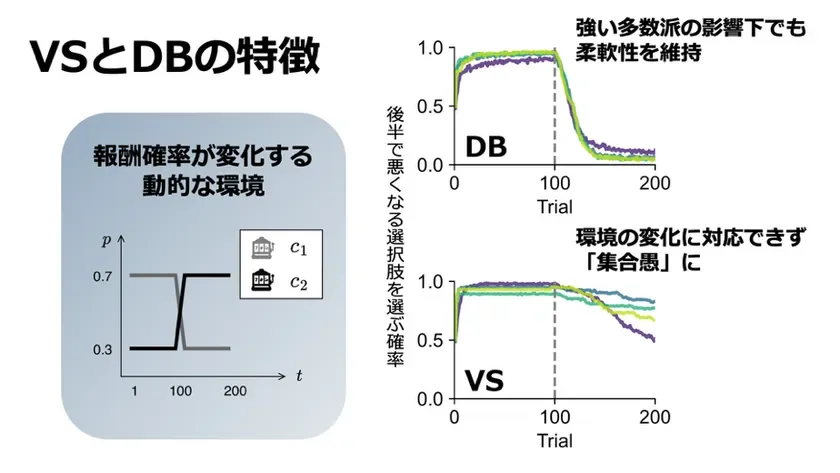
図2 社会学習アルゴリズムが生み出す集団レベルの帰結。このシミュレーションでは報酬確率が異なる2つの選択肢があり、それらの報酬確率が途中で逆転する、という状況を想定しました。DB型は環境の変化に対応し、VS型は「時代遅れの選択肢」に固着してしまいます。
そして最も重要な発見は、これら2つのタイプが集団の中で安定して共存できる(「進化的安定性」)という点です。さらに、単独では環境変化に弱いVS型の人々が、より柔軟なDB型の人々と一緒にいることで、集団全体として意思決定のパフォーマンスが大きく向上することが示されました。
この結果は、意思決定の効率性(素早く良い選択肢に集中すること)と柔軟性(選択肢の変化に対応すること)という、両立が難しい2つの目標を達成するために、集団内の多様性が非常に大切であることを示唆しています。
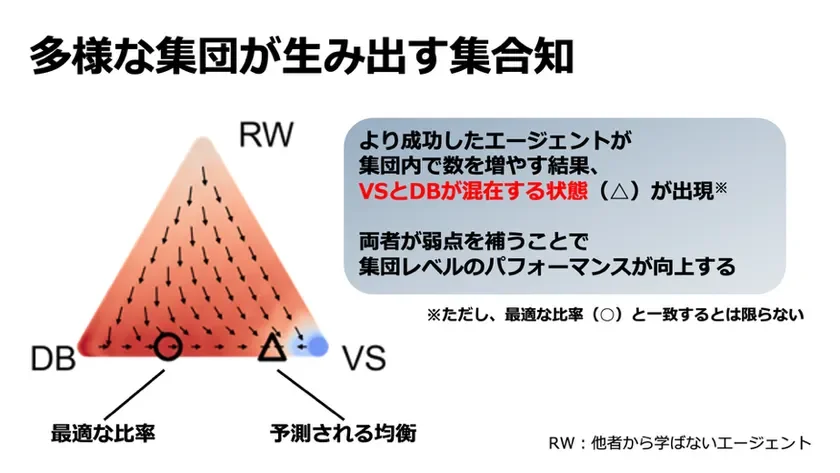
図3 進化ダイナミクスの可視化。DB型とVS型が適切な比率で混在している場合に、互いの弱点を補うことで集団レベルで高いパフォーマンスが実現しうることが示されました。
人間とAIが共存する社会への示唆
今回の研究で得られた知見は、人間とAIが共に生きる現代やこれからの情報空間において、より良い集団での意思決定をどのようにデザインしていくべきか、という重要な問いにヒントを与えます。
災害やパンデミックのような不確実な状況で起こりがちな過剰な同調圧力や誤情報の拡散、陰謀論の広がりといった社会問題に対して、この研究は、どのようにすれば社会全体が賢く対応できるかを考えるための基礎となるでしょう。
本研究成果は、2025年11月24日に米国科学アカデミー紀要(Proceedings of the National Academy of Sciences of the United States of America)にて公開されました。
論文情報:
-
雑誌名: Proceedings of the National Academy of Sciences of the United States of America
-
題名 : How social learning enhances-or undermines-efficiency and flexibility in collective decision-making under uncertainty
-
著者名: Hidezo Suganuma, Kentaro Katahira, Hisashi Ohtsuki, and Tatsuya Kameda*
-
DOI : 10.1073/pnas.2516827122
用語解説
-
強化学習(reinforcement learning)
コンピューターが環境から「報酬」をもらいながら、最適な行動を学習していくAIの手法です。ロボットの制御やAIの開発にも広く使われています。 -
エージェントベースシミュレーション(agent-based simulation)
個々のコンピューター上の主体(エージェント)がシンプルなルールに従って動く様子を再現し、集団全体の動きを調べる研究方法です。 -
進化ダイナミクス(evolutionary dynamics)
ここでは、集団の中でより良い成果を出した戦略(社会学習のタイプ)が、次第に数を増やしていくプロセスのことを指します。

