
2026年、韓国のAI半導体産業が大きく飛躍する年になるかもしれません。
2025年12月10日、ソウルで開催された「2025AI半導体未来技術カンファレンス(AISFC 2025)」では、韓国産AI半導体の性能を客観的に評価する新しい基準「K-Perf」が正式にスタートしました。また、2026年にはAI分野への投資が大幅に増え、約9.9兆ウォン(日本円で約1兆円)もの予算が投じられることが発表され、AI分野で世界トップ3に入るための基盤が示されました。

AI分野への大規模投資と目標
韓国のペ・ギョンフン副首相兼科学技術情報通信部長官は、AI半導体カンファレンスで、韓国がAI分野で世界トップ3の強国を目指すと宣言しました。長官は、AI半導体の性能がすでに成熟段階にあることを強調し、K-Perfがその出発点になると述べました。

2025年が基盤を固める年であるならば、2026年はAI強国として本格的に前進する年と位置付けられています。政府は2026年の研究開発予算を約35兆ウォン規模とし、そのうちAIへの投資はこれまでの3倍にあたる9.9兆ウォンを割り当てる計画です。これは、GoogleのTPUがNVIDIAのGPUに匹敵する効率性を示したように、持続的な投資を通じてAIエコシステム全体の成長を支援する狙いがあります。
新しい性能評価基準「K-Perf」とは?
AISFC 2025の重要な発表の一つが、AI半導体の性能をより実用的な視点から評価する「K-Perf」の始動です。これまでの業界標準である「MLPerf」は、標準化された評価方法があるものの、実際の利用環境での性能とのずれや、学習中心で推論の評価が限られるという課題がありました。
そこで、韓国政府は、AI半導体を供給する企業と、クラウドサービスやAIを活用する企業が協力して評価を行う新しい枠組みを構築しました。
K-Perfには、FuriosaAI、Rebellions、HyperAccelといった供給側の企業に加え、Naverクラウド、KTクラウド、NHNクラウド、サムスンSDS、LG CNS、SKテレコム、LG AI研究院、カカオエンタープライズ、モレーといった需要側の企業が参加しています。
主要なテストでは、Meta Llama 3.1やEXAONE 4.0といった大規模なAIモデルが使われ、入力・出力の長さ、同時に利用するユーザー数、精度、トークン処理速度、消費電力などが測定されます。これらの結果は、具体的な数値とグラフで分かりやすく示されます。
K-Perfは、供給側と需要側の間で大きかった性能認識のずれを解消するための第一歩であり、将来的にはスマートフォンなどのデバイスに搭載されるAI(オンデバイスAI)への拡張も計画されています。

AI半導体企業の取り組みと未来の展望
カンファレンスでは、韓国の主要AI半導体企業による発表も行われました。特にFuriosaAIは、2026年1月に第2世代NPU「RNGD」を商用化し、その後も高性能なRNGD+やRNGD+ Maxを投入する計画を明らかにしました。

FuriosaAIのSDK(ソフトウェア開発キット)もバージョン4.0に進化し、AIの推論処理を効率化したり、AIモデルのメモリ利用を最適化したりする機能が追加されています。これにより、NPUとITインフラの連携がさらに強化されます。

FuriosaAIは、OpenAIの大規模言語モデル「gpt-oss-120B」を2枚のRNGDカードで動かすデモンストレーションも披露しました。このモデルは通常、非常に多くのメモリと高性能なGPUを必要としますが、FuriosaAIは独自の最適化技術により、約5.8ミリ秒という超低遅延での応答速度を実現しました。

支援機関による2026年AI半導体事業の方向性
情報通信企画評価院(IITP)は、2026年のAI半導体に関する研究開発(R&D)事業計画を発表しました。IITPは、AI半導体の技術開発、事業化、人材育成を支援する重要な機関です。
2025年には、NPU企業の成長を支援する取り組みや、オンデバイスAI、PIM半導体(メモリ内で計算を行う半導体)の開発支援が行われました。2026年には、LPDDR6-PIMを基盤としたAIアクセラレータや、AI半導体チップ間の通信を最適化するソフトウェアの開発など、12件の新しい課題に取り組む予定です。

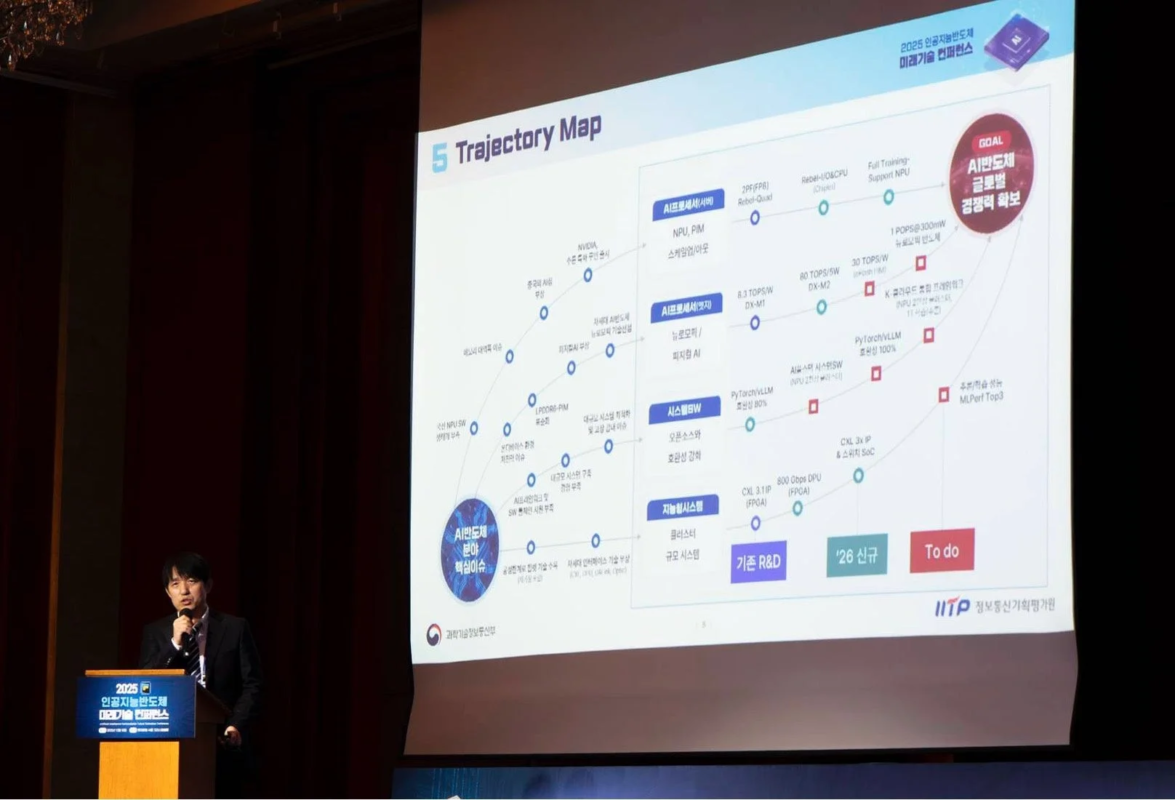
また、情報通信産業振興院(NIPA)は、AI半導体の設計、製造、検証、そして量産まで、生産プロセス全体を支援しています。2025年には、16社から27種類の韓国産AI半導体が市場に登場し、500万ドルを超える輸出実績を上げました。2026年には、完成した製品を基盤に、需要の創出、制度の改善、人材育成、そして海外進出までを包括的に支援する方針です。

世界市場での競争力強化へ
AI半導体の設計から生産まで一貫して行える国は、世界でも韓国、台湾、米国の3カ国のみと言われています。韓国は、メモリ半導体とファウンドリー(半導体の受託生産)の強みを活かし、急速に競争力を高めています。
2025年に16社から27種類のNPUが登場したことは、世界的に見ても注目すべき成果です。K-Perfの導入は、国内の需要企業の要望を反映した成功事例を生み出し、その実績を基に海外市場での契約獲得につなげるための重要な取り組みとなるでしょう。2026年における韓国産AI半導体の世界展開に期待が寄せられています。


