
日本各地の「方言」を学習データに!
AI(人工知能)技術が進化する中、私たちの言葉をより正確に理解するAIが求められています。そんな中、Visual Bank株式会社が提供するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」から、新しいデータセットが登場しました。
今回提供が始まったのは「日本語・1話者・地域の方言の独り語り音声データ」です。これは、日本各地の様々な方言を話す人が、一人で語る音声を収録した特別なデータセットです。

どんな方言が聞けるの?
このデータセットには、関西弁、岡山弁、伊予弁、土佐弁など、地域ごとの特徴ある方言が収録されています。話者は20代から60代までの男女で、日常的な話題や自分の考えについて独り語りをする音声が中心です。台本を参考にしながらも、まるで本当に話しているかのような自然なリズムや間、地域ならではの言い回しが含まれているのが大きな特徴です。
AI開発にどう役立つ?
この方言音声データは、主に以下のようなAIの開発や研究に役立つと期待されています。
-
音声認識(ASR)の精度向上
標準語だけでなく、方言を話す人の声も正確に聞き取れるAIを作るために使えます。例えば、コールセンターや音声入力システムで、より多くの利用者の言葉に対応できるようになるでしょう。 -
音声言語モデルの性能評価
AIが方言を含む様々な日本語をどれだけ理解できるか、その能力を評価するために利用されます。 -
方言音声合成の自然性向上
方言特有のイントネーションやリズムをAIに学習させることで、より自然な方言を話すAIの開発に貢献します。 -
教育・学習教材
音声処理や音声AIを学ぶための教材としても活用できます。
Qlean Datasetは、開発の目的に合わせて、音声データの設計や新しい収録にも対応しています。これにより、実際の利用環境を想定したAIの検証や、用途に合わせた音声モデルの開発が可能になります。
データセットの詳しい情報やサンプルは、以下のリンクから確認できます。
Qlean Datasetについて
「Qlean Dataset」は、Visual Bank株式会社のグループ会社である株式会社アマナイメージズが提供する、AI学習用のデータソリューションです。画像、動画、音声、3D、テキストなど、様々な形式のデータを取り扱っており、研究用途はもちろん、商用利用も安心して行えるように権利処理が済んでいます。
AI開発に必要なデータを集めたり準備したりする手間を減らし、法的なリスクなくAIを開発できる環境を支援しています。
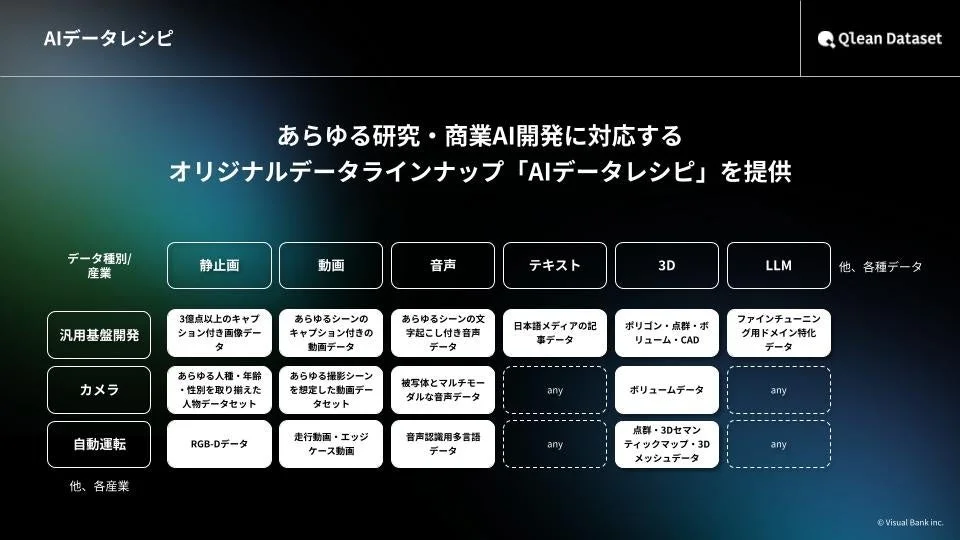
Qlean Datasetの強み
Qlean Datasetは、以下の点でAI開発をサポートします。
-
多様なデータ形式に対応
画像、動画、音声、3D、テキストなど、様々な種類のデータを提供できます。 -
カスタムデータも構築可能
既存のデータだけでなく、お客様の要望に応じて新しいデータを撮影・収録・収集して提供することも可能です。 -
権利処理済みで安心
著作権や肖像権などの権利がクリアになっているため、研究でもビジネスでも安心して利用できます。
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」ことをミッションに掲げ、AI開発力を高める次世代型のデータインフラを提供しています。
Qlean Datasetに関する詳細は、以下のサイトをご覧ください。
また、Visual Bank株式会社および株式会社アマナイメージズの企業情報はこちらです。

