
Visual Bank株式会社が展開するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」から、新しい音声データセットの提供が始まりました。
このデータセットは、「日本語・2話者・コメディテーマトーク音声コーパスデータセット」と名付けられ、AI(人工知能)がより自然で人間らしい会話を理解し、応答するために役立つように作られています。

自然な「ボケ・ツッコミ」も学べるAI学習用データ
今回提供が始まったデータセットには、20代から50代の男女2名による日本語の自然な会話が約330時間分も収録されています。この会話は、台本なしの自由な雑談形式で、ユーモアや笑いを交えた軽快なやり取りが特徴です。まるで友達同士の会話のように、即興的な反応や話題の脱線、さらには「ボケ」や「ツッコミ」といった、日本語の日常会話ならではの要素がたくさん含まれています。
このようなリアルな会話データには、二人の話者が交互に話したり、時には同時に話したりする様子も含まれています。これにより、AIが「誰がいつ話しているか」を判断したり、「会話の流れ」を理解したりするための学習に活用できるのです。
データはMP3またはWAV形式で提供され、1つの音声は約5分から60分と、様々な長さで収録されています。
サンプル詳細はこちらで確認できます。
https://qleandataset.visual-bank.co.jp/lineup/pn-020
AIの会話能力を向上させる多様な活用方法
このデータセットは、様々な場面でAIの能力を高めるために使われることが期待されています。
研究での活用例
-
会話の流れを分析する研究: AIが、二人の話者がいつ交代して話しているか、話題がどう変わっていくかなどを分析する技術の検証に役立ちます。
-
雑談を理解するAIの研究: 台本がない自然な雑談を通して、AIが特定の目的がない会話の展開や、適切な返答の仕方を学ぶ研究に活用できます。
産業での活用例
-
音声対話AIの開発: 音声アシスタントや、お客様と会話するサービスなどで、AIがより自然な会話の流れで応答したり、話の内容を理解したりするモデルの開発に利用できます。
-
話者識別・会話交代技術の検証: AIが会話の中で「誰が話しているか」を正確に識別したり、話者が交代するタイミングを検出したりする技術の検証に活用できます。
教育での活用例
- AI教育の教材: 大学や専門学校で、音声認識や対話AIを学ぶ際の教材として、実際の会話が持つ特有の課題を解決する演習データとして利用できます。
Qlean Datasetについて
「Qlean Dataset」は、Visual Bank株式会社の子会社である株式会社アマナイメージズが提供する、AI学習用のデータソリューションです。画像、動画、音声、3D、テキストなど、様々な種類のデータを提供しており、研究だけでなく、ビジネスでの利用も安心して行えるように、著作権などの権利処理がされたデータを提供しています。
さまざまな業界のAI開発に対応する機械学習用データセットのラインナップ「AIデータレシピ」を継続的に増やしており、AI開発の現場でのデータ収集や準備にかかる手間を減らし、法的なリスクなくAI開発を進められるようサポートしています。
Qlean Datasetサイトはこちらです。
https://qleandataset.visual-bank.co.jp/
AIデータレシピのページはこちらです。
https://qleandataset.visual-bank.co.jp/lineup
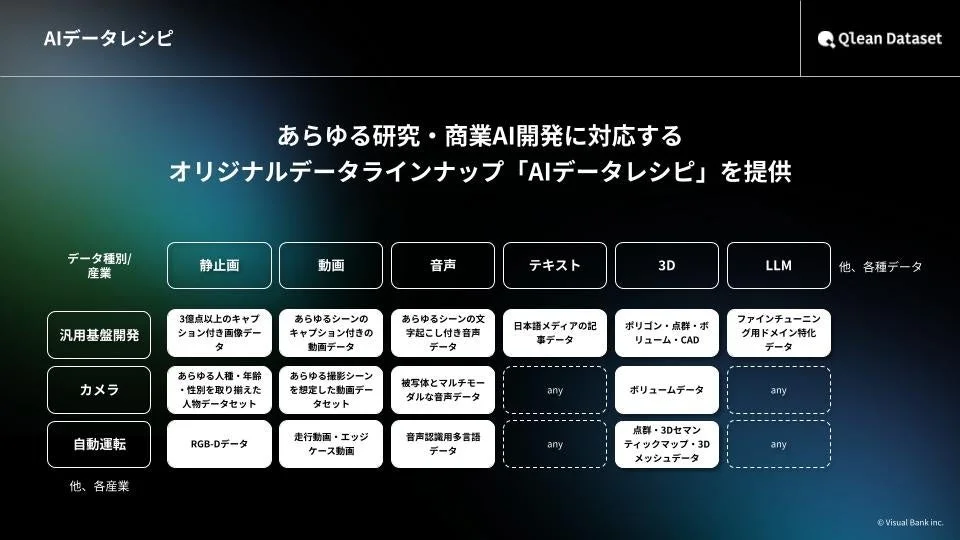
Qlean Datasetの特長
Qlean Datasetは、AI開発に必要なデータセット(データ素材、アノテーション、キャプションなど)を「AIデータレシピ」から提供しています。

主な強みは以下の4点です。
- 安価でスピーディーなデータ提供: 初期費用を抑えながら、必要なデータを素早く手に入れられます。
- 多様なデータ形式に対応: 画像、動画、音声、3D、テキストなど、様々な形式のデータ開発に柔軟に対応します。
- 独自データ構築にも対応: 「AIデータレシピ」にない特別なデータも、要望に応じて準備・提供が可能です。
- 権利処理済みで安心: 著作権や肖像権などの権利がクリアされているため、研究やビジネスでの利用も完全に安心です。最新のAI倫理や法制度にも対応しています。

Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化する次世代のデータインフラを構築・提供しているスタートアップ企業です。漫画家をサポートするAI補助ツール『THE PEN』の提供や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社に持っています。
Visual Bank企業URL:
https://visual-bank.co.jp/
アマナイメージズ企業URL:
https://amanaimages.com/about/

