
株式会社ELYZAは、日本語の理解や対話の質を高める新しいAIモデル「ELYZA-LLM-Diffusion」シリーズを開発し、商用利用可能な形で公開しました。

このモデルは、KDDI株式会社のGPU基盤を利用して開発され、日本語における知識や指示に従う能力が強化されています。現在、デモも公開されており、実際に試すことができます。
拡散型大規模言語モデル(dLLM)とは?
「拡散型大規模言語モデル(Diffusion Large Language Model、略称: dLLM)」は、もともと画像を作るAIで使われていた「拡散モデル」という技術を、文章作りに応用した新しいタイプのAIです。
これまでのAI(自己回帰モデル、略称:ARモデル)が文章を左から右へ一つずつ順番に作っていくのに対し、dLLMは、まずノイズだらけのデータを作り、そこから段階的にノイズを取り除いていくことで、きれいな文章を作り出します。まるで、ぼやけた写真から少しずつ鮮明な画像を作り出すようなイメージです。
この方法の大きなメリットは、文章を一つずつ作る必要がないため、設計によってはより少ない処理で文章を生成できる点です。これにより、AIが文章を作るスピードが上がり、使う電力も減らせる可能性があります。
しかし、dLLMは開発に手間がかかることや、まだ広く使われるための仕組みが整っていないため、現時点での利用は限られています。ですが、基礎研究は進んでおり、将来的に実用化が進むかもしれないと期待されている技術です。また、これまでに公開されているdLLMの多くは英語を中心に学習されているものがほとんどでした。
ELYZAが開発したモデルについて
今回ELYZAが開発したのは、HKU NLP Groupが公開しているdLLM「Dream-org/Dream-v0-Instruct-7B」をベースにしたモデルです。これに日本語のデータを追加で学習させたり、指示に従う学習を行ったりすることで、日本語の知識力や指示への対応能力を高めました。
現在公開されているモデルは以下の2つです。
-
ELYZA-Diffusion-Base-1.0-Dream-7B
「Dream-v0-Instruct-7B」に日本語のデータを追加で学習させたモデルです。
https://huggingface.co/elyza/ELYZA-Diffusion-Base-1.0-Dream-7B -
ELYZA-Diffusion-Instruct-1.0-Dream-7B
「ELYZA-Diffusion-Base-1.0-Dream-7B」に指示に従う学習を行ったモデルです。
https://huggingface.co/elyza/ELYZA-Diffusion-Instruct-1.0-Dream-7B
dLLMとこれまでのARモデルがどのように文章を作るか、その違いは以下の画像でも確認できます。
また、このモデルを使ったチャット形式のデモもHugging Face Hubで公開されています。アクセスが集中すると、処理に時間がかかる場合があるため、注意が必要です。

モデルの開発過程や技術的な詳細、評価に関する詳しい情報は、公式テックブログで解説されています。

モデルの性能について
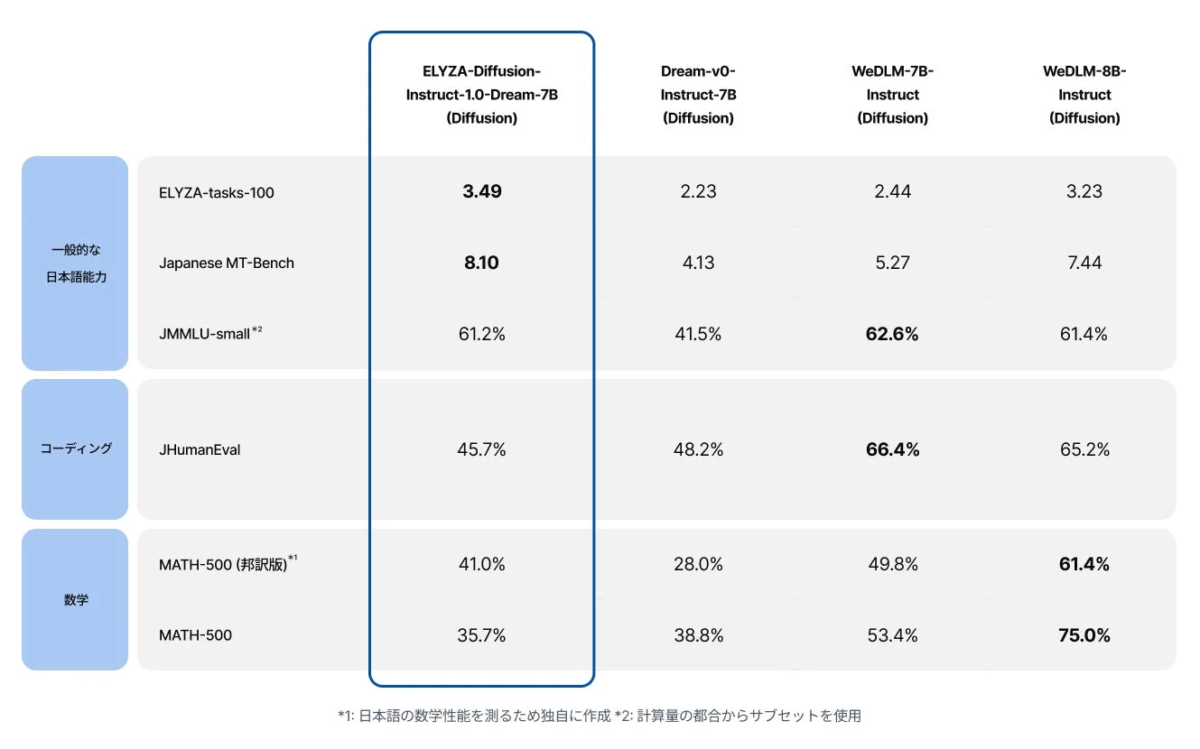
今回開発されたモデルが日本語の課題に対してどれくらいの性能を発揮するのかを確認するため、日本語を中心とした評価が行われました。その結果、以下の画像に示すように、一般的な日本語能力を問われるタスクでは、「ELYZA-Diffusion-Instruct-1.0-Dream-7B」が、他のオープンなdLLMと比べても同等か、より優れた性能を見せています。
研究の狙い
AIの利用が広がるにつれて、AIが使う電力の量が増え、発電量の不足やAI用データセンターの不足が世界的な問題になっています。そのため、これからも生成AIを活用していくには、AIモデルが効率的に文章を作ったり、学習したりすることが重要になってきています。
dLLMは、少ない処理回数で文章を作れるという特徴があるため、これまでのARモデルと比べて、文章生成にかかる時間が短く、電力の消費も抑えられる可能性があります。この研究をさらに進めることで、電力効率の良い高性能な日本語LLMの開発がより加速することが期待されます。
ELYZAは、これからも最先端のAI研究開発に取り組み、その成果をできる限り公開・提供することで、日本におけるLLMの社会での活用を推進し、自然言語処理技術の発展を支援していくとしています。
ELYZA会社概要
株式会社ELYZAは、「未踏の領域で、あたりまえを創る」という理念のもと、日本語の大規模言語モデルに特化し、企業との共同研究やクラウドサービスの開発を行っています。最先端技術の研究開発とコンサルティングを通じて、企業成長に貢献する形で大規模言語モデルの導入を進めています。
-
社名:株式会社ELYZA
-
所在地:〒113-0033 東京都文京区本郷3-15-9 SWTビル 6F
-
代表者:代表取締役 曽根岡侑也
-
設立:2018年9月

