
Qlean Datasetが、AI開発のための新たなデータセット「日本語・2話者・スポーツテーマトーク音声コーパスとトランスクリプト」の提供を始めました。
Visual Bank株式会社が子会社のアマナイメージズ株式会社を通じて提供するAI学習用データソリューション「Qlean Dataset」は、自動音声認識(ASR)、自然言語処理(NLP)、大規模言語モデル(LLM)といった音声や言語を扱うAIの開発を支援しています。

スポーツに特化した自然な対話音声データ
今回提供されるデータセットは、Qlean Datasetの機械学習用データセットシリーズ『AIデータレシピ』に加わります。このデータには、スポーツや競技をテーマに、日本人の男女2名が自由に会話する日本語音声と、その内容を正確に書き起こしたテキスト(トランスクリプト)が収録されています。
会話は台本なしで行われ、競技経験の共有、試合の振り返り、戦術や記録に関する意見交換、観戦の感想など、スポーツに関する多様な話題が自然な形で展開されます。話者の交代や相づち、発話の重なりといった実際の会話の特徴が反映されており、音声認識や対話処理といった、実際のAIシステムで使われることを想定した研究開発に役立ちます。
Qlean Datasetは、研究から商用開発まで幅広い用途で使えるよう、著作権などの権利処理や利用条件をきちんと整理したAI開発用データを提供しています。この新しいデータセットも、スポーツ分野に特化した日本語の対話データを使ってAIを検証する環境を整えることを目的に提供されます。
データセットの概要
| データ種別 | 音声、テキスト |
|---|---|
| 被写体属性 | 日本人、20代〜50代の男女 |
| データ形式 | 音声データ:wav,mp3 テキストデータ:txt,json,csv |
| 収録時間 | 計約200時間(1音声約5分〜60分) |
| 音声レート | 44.1kHz |
| 対象のシーン | ・2名がスポーツ経験・競技分析・観戦感想を共有し合うシーン |
| ・試合の振り返りや運動に関する話題が自然に展開される場面 | |
| ・台本制御なしで自由なテンポで進む対話 | |
| ・戦術・記録・体験談の紹介などを含む会話 | |
| ・スポーツ領域の多様な話題が展開される対話シーン |
サンプルページはこちらから確認できます。
ユースケースの例
このデータセットは、様々なAI開発に活用できます。
研究での活用
-
対話型音声認識モデルの評価・分析: 2人の自然な会話音声を使って、話者の交代や発話の重なりがある状況での音声認識の精度や、どのような間違いが起こりやすいかを分析できます。
-
対話理解・談話構造の研究: スポーツに関する意見交換や説明が続く対話データを使って、話者の意図を推測したり、会話の構造を分析したり、会話の区切りを研究したりするのに役立ちます。
産業での活用
-
音声入力型対話AI・ボイスアシスタントの開発: スポーツ情報を提供する音声インターフェースや、ユーザーと会話するAIにおいて、実際の会話に近い対話音声を使って、認識や応答モデルの性能を検証できます。
-
コールセンター・対話ログ解析技術の検証: 2人の自然な会話構造を利用して、話者を区別したり、誰が話しているかを検出したりする音声対話解析技術の事前検証に役立ちます。
Qlean Datasetについて
『Qlean Dataset』は、Visual Bankの子会社である株式会社アマナイメージズが提供する、商用利用が可能なAI学習用データソリューションです。画像、動画、音声、3D、テキストなど、様々な形式のデータに対応し、研究と商用のどちらの目的でも安心して利用できる環境を整えています。
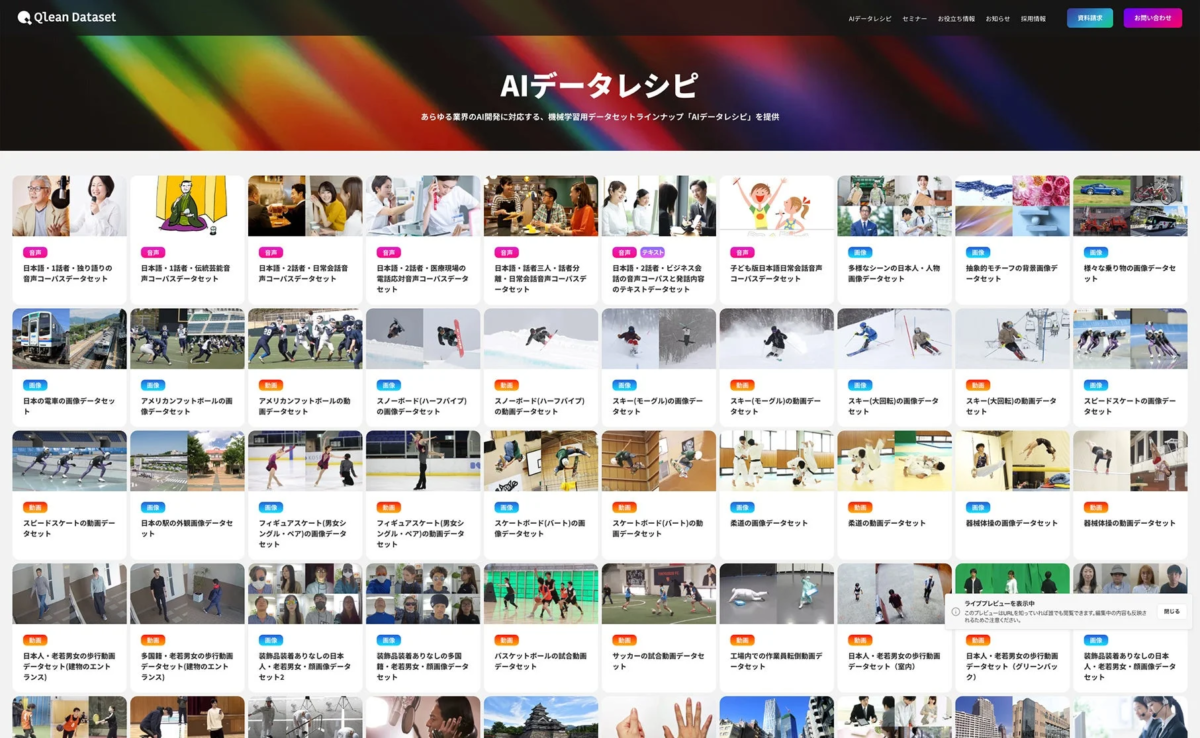
株式会社千葉ロッテマリーンズや株式会社東洋経済新報社といったデータパートナーと協力し、特定の業界に特化したデータや最新のトレンドに合わせたデータセット『AIデータレシピ』を継続的に増やしています。
Qlean Datasetは、AI開発現場でのデータ収集や準備の負担を減らし、著作権などの権利が明確で、法的なリスクのないAI開発環境の構築を支援します。
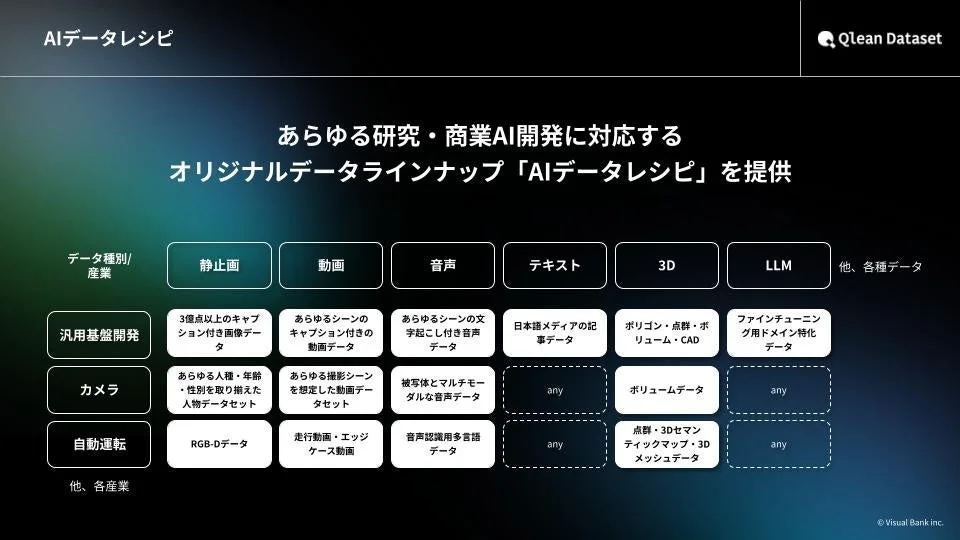


『Qlean Dataset』が提供する『AIデータレシピ』の主な特徴は以下の通りです。
-
すべての被写体から同意を取得しています。
-
既存のデータは最短1日で納品可能です。
-
独自のデータを構築するためのカスタム撮影・収録・収集にも対応しています。
Visual Bank株式会社について
Visual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大限に高める次世代型データインフラを構築・提供するスタートアップ企業です。漫画家をサポートするAI補助ツール『THE PEN』のほか、AI学習用データセット開発サービス『Qlean Dataset(キュリンデータセット)』を提供する株式会社アマナイメージズを100%子会社としています。
また、Visual Bankは国の研究開発プログラム「GENIAC」にも採択されており、社会へのAI実装に向けた取り組みを加速させています。

