Turing株式会社は、AIが画像や動画を理解する技術「コンピュータ・ビジョン」に関する世界最高峰の国際会議「CVPR 2026(Computer Vision and Pattern Recognition Conference 2026)」において、同社の研究開発チームによる2本の論文が採択されたことを発表しました。
CVPRは、毎年世界中の大学や研究機関、企業から多数の論文が投稿され、厳格な審査を経て採択論文が決定される、この分野を代表する学術イベントです。画像理解や、異なる種類のデータ(画像とテキストなど)を組み合わせて学習する「マルチモーダル学習」といった幅広いテーマが議論されています。
テキストだけでAIを賢くする新手法「Text-Printed Image」
1本目に採択された論文は、「Text-Printed Image: Bridging the Image-Text Modality Gap for Text-centric Training of Large Vision-Language Models」です。
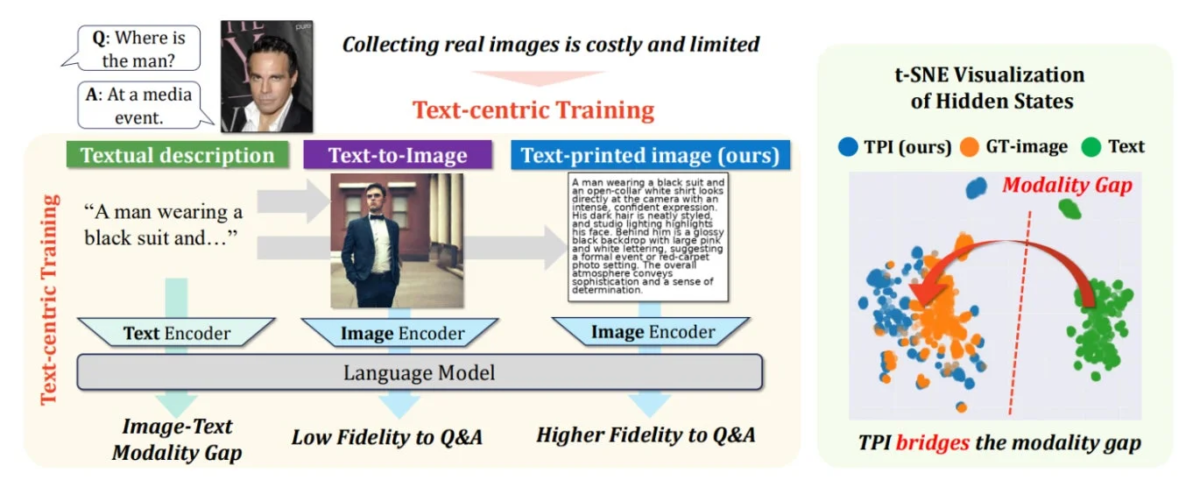
この論文では、実際に撮影された画像を使わず、テキスト(文章)の記述だけで大規模なAIモデルを強化する新しい方法「Text-Printed Image」が提案されました。この技術は、与えられたテキストを白いキャンバスにそのまま描いて合成画像を作ることで、テキストが持つ意味を保ったまま、AIが画像を学習する既存の仕組みに組み込めるのが特徴です。
複数のAIモデルと評価基準で検証した結果、一般的な画像生成AI(拡散モデル)で作られた画像を使うよりも、テキストを中心にAIを効果的に学習させられることが確認されました。
-
論文リンク(arXiv): https://arxiv.org/abs/2512.03463
-
テックブログ: https://zenn.dev/turing_motors/articles/017e6d6253632f
リアルな3D空間を正確に再現する「P2GS」
2本目の採択論文は、「P2GS: Physical Prior-guided Gaussian Splatting for Photometrically Consistent Urban Reconstruction」です。
この論文で提案された新手法「P2GS」は、さまざまな条件で撮影された画像から、高品質な3次元空間を再現する技術です。これまでの方法では、異なるカメラで撮影された画像の明るさや色の違いが、そのまま3次元モデルに混ざり込み、不自然な明るさのムラや色のずれが生じることがありました。
しかし、「P2GS」はこれらの問題を解消し、実際の空間の明るさをより正確に推定できます。これにより、異なるカメラや明るさの条件下でも、一貫した見た目を保つ3次元空間の再現が可能となり、自動運転のシミュレーションなどに適した安定した仮想環境の実現に貢献するとされています。
自動運転の未来を切り拓く研究
今回採択された2本の論文は、AIモデルの学習をより効率的にしたり、シミュレーション環境をより高度にしたりすることで、自動運転システムの開発プロセスを効率化することに貢献します。これにより、より安全で安定した自動運転システムを構築するための基盤が強化されることになります。
Turing株式会社は、今後も最先端の研究開発を続け、あらゆる状況で車が人間の代わりに運転操作を行う「完全自動運転」の実現を目指し、技術基盤の強化を進めていくとのことです。
Turing株式会社は、センサーからの情報から直接運転操作までを一貫して行う「E2E(End-to-End)自動運転AI」と、人間社会の常識や背景を理解した大規模な基盤モデルを同時に開発し、これらを統合することで、完全自動運転の実現を目指しているスタートアップです。
採用情報
Turing株式会社は、日本発の完全自動運転を実現し、世界を変える仲間を募集しています。
-
採用ページ: https://tur.ing/jobs
-
Connpassページ (イベント情報など): https://turing.connpass.com/