
AI学習に役立つ新しいデータセットが登場
AI(人工知能)の技術は日々進化しており、私たちの生活のさまざまな場面で活用されています。特に、AIが人間の言葉を理解したり、人間のように話したりする技術は、より自然で便利なAIサービスを作る上でとても重要です。
Visual Bank株式会社が提供するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」は、このAI技術をさらに発展させるための新しいデータセットの提供を開始しました。

今回提供されるのは、「海外文学の朗読音声とトランスクリプト」というデータセットです。これは、海外の文学作品を日本語に翻訳した文章を、一人の日本人話者が落ち着いた声で朗読した音声と、その音声にぴったりの正確なテキストデータ(トランスクリプト)がセットになっています。
なぜ海外文学のデータがAI学習に良いの?
このデータセットの特徴は、普段の会話とは違う、文学作品ならではの「書き言葉」で構成されている点です。格調高い表現や、少し複雑な文章のつながり(修飾関係)が多く含まれているため、AIがより高度な日本語を理解し、表現する能力を身につけるのに役立ちます。
データセットの概要
-
データ種別: 音声、テキスト
-
被写体属性: 日本人
-
データ形式: 音声データ:mp3
-
収録時間: 1音声30秒〜90分
-
音声レート: 44.1kHz / 48kHz
-
対象のシーン: 海外文学作品の文章を日本語訳文として朗読するシーン
サンプル詳細はこちらで確認できます。
https://qleandataset.visual-bank.co.jp/lineup/pn-040
このデータセットでAIは何ができるようになるの?
この新しいデータセットは、さまざまなAI技術の開発に活用されることが期待されています。
-
AIが人の声をより正確に聞き取る(音声認識モデルの向上)
長い文章や複雑な表現が含まれる文学作品の音声をAIに学習させることで、AIが前後の文脈を理解し、より正確に文字に変換できるようになります。例えば、会議の議事録作成や、動画の字幕生成の精度が上がることが期待されます。 -
AIがより自然な声で話す(音声合成エンジンの開発)
オーディオブックのように、物語の情景が伝わるような表現力豊かなナレーションをAIが生成できるようになります。ニュース記事の自動読み上げサービスなどでも、より聞き取りやすく、感情を抑えつつも表現豊かな声が実現するでしょう。 -
日本語を学ぶAIや、読み上げ支援AI
正しい日本語の発音データとして活用することで、日本語を学ぶ外国人の方の発音をAIが評価したり、視覚に障がいを持つ方々が本を読む際に、自然で疲れにくい声で読み上げてくれるAIの開発にもつながります。 -
高度な文章を理解するAI(LLMのファインチューニング)
論理的な構造を持つ文学作品の音声とテキストをAIに学習させることで、文章の要約や文学的な表現の翻訳能力が高いAI(大規模言語モデル、LLM)を開発するのにも役立ちます。
『Qlean Dataset』について
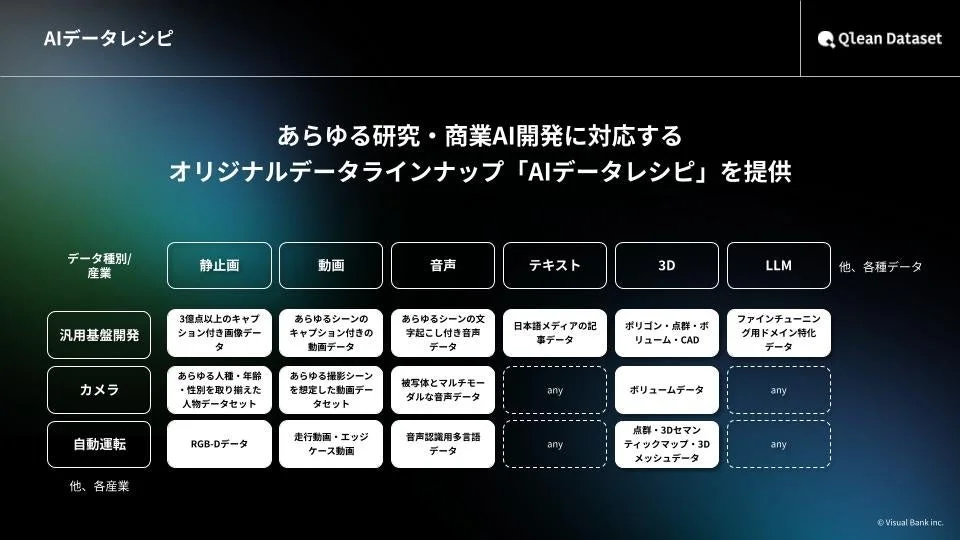
「Qlean Dataset」は、AI開発に必要な学習データを幅広く提供するソリューションです。画像、動画、音声、3D、テキストなど、さまざまな形式のデータを取り扱っており、研究から商用利用まで、安心して使えるデータを提供しています。
「AIデータレシピ」というオリジナルのデータラインナップを通じて、業界に特化したデータや最新のトレンドに合わせたデータを継続的に増やしています。これにより、AI開発現場でのデータ集めや準備にかかる手間を減らし、安心してAI開発に取り組める環境をサポートしています。


-
Qlean Datasetサイト:https://qleandataset.visual-bank.co.jp/
Visual Bank株式会社について
Qlean Datasetを提供するVisual Bank株式会社は、「あらゆるデータの可能性を解き放つ」をミッションに掲げ、AI開発力を最大化するデータインフラを提供するスタートアップ企業です。漫画家をサポートするAI補助ツール『THE PEN』や、AI学習用データセット開発サービス『Qlean Dataset』を提供する株式会社アマナイメージズを100%子会社としています。
Visual Bankは、国の研究開発プログラム「GENIAC」にも採択されており、社会に役立つAI技術の実用化に向けて積極的に取り組んでいます。
-
Visual Bank企業URL:https://visual-bank.co.jp/
-
アマナイメージズ企業URL:https://amanaimages.com/about/

