AIの新たな進化:高次元で複雑なデータも予測できる「HetAESN」が登場
近年、様々な分野でAI(人工知能)の活用が進んでいます。特に、時間の流れとともに変化するデータ、例えば株価の変動、気象予報、生体信号の解析などを予測する「時系列予測」は、私たちの生活やビジネスにおいて非常に重要です。
しかし、現実世界のデータはとても複雑で、従来のAIモデルでは対応しきれない課題がありました。この課題を解決するため、千葉工業大学、基礎生物学研究所、兵庫県立大学の研究チームが、新しいAI技術「HetAESN(Heterogeneous Assembly Echo State Network)」アーキテクチャを開発しました。この技術は、高次元でマルチスケール(複数の時間スケールを持つ)な時系列予測において、これまでのモデルを大きく上回る性能を発揮することが期待されています。

従来のAIモデルが抱えていた二つの壁
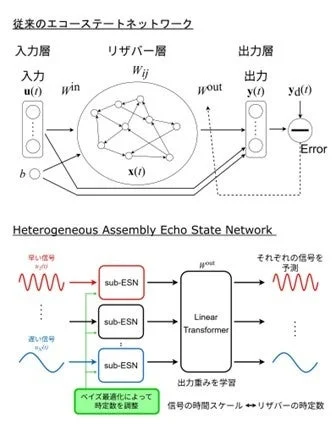
AIの中でも、脳の神経回路網を模した「リカレントニューラルネットワーク(RNN)」の一種である「リザバーコンピューティング(RC)」は、高速かつ低コストで学習できるという特徴があり、限られた計算資源で動く「エッジAI」(スマートフォンやIoT機器などに搭載されるAI)への応用が注目されています。
しかし、RCの代表的なモデルである「Echo State Network(ESN)」を、画像・動画認識や気象予測といった複雑なタスクに適用しようとすると、主に二つの壁に直面していました。
- 高次元性(たくさんの種類のデータ):多数のセンサーデータや画像データのように、非常に多くの情報が同時に動くデータを扱う場合、AIの内部構造を大きくする必要があり、それに伴って計算コストが膨大になるという問題です。
- マルチスケール性(速い変化と遅い変化の混在):現実世界の現象は、瞬間的に速く変化する部分と、ゆっくりと推移する部分が混ざっています。従来のESNは、これらを一律に処理しようとするため、複雑なパターンの時系列データを十分に捉えきれないという課題がありました。
これまでの研究では、高次元性に対応するためにデータを分割して処理する「Assembly ESN (AESN)」や、マルチスケールに対応するために複数の時間特性を導入する「Diverse-Timescale ESN (DTS-ESN)」などが提案されてきましたが、これら二つの特性を同時に効率よく扱うことはできていませんでした。
HetAESNアーキテクチャの登場
今回開発された「HetAESN」は、従来のAESNの構造をさらに進化させたモデルです。AESNは、高次元の入力データをいくつかの部分に分割し、それぞれを複数のAI(サブリザバー)で並行して処理することで、高次元データによる性能の低下を防ぐ仕組みを持っています。
HetAESNは、この分割された各サブリザバーに、入力される信号の特性に合わせて最適な、それぞれ異なる「時定数」(AIが過去の情報をどれくらいの速さで忘れ、新しい情報を取り入れるかの時間的な特性)を割り当てます。この「不均一な(Heterogeneous)」設計により、各サブリザバーは、速い変化の信号と遅い変化の信号の両方に柔軟に適応し、より効果的に追跡・予測できるようになりました。
予測性能の検証と分析
研究チームは、tc-VdP、Hindmarsh-Rose(HR)、tc-Lorenzという3種類のカオス時系列システム(複雑な動きをするデータ)を用いて、HetAESNの予測性能を検証しました。その結果、tc-VdPとHRのタスクにおいて、HetAESNは従来のESNやAESNよりも統計的に有意に高い予測精度を達成しました。
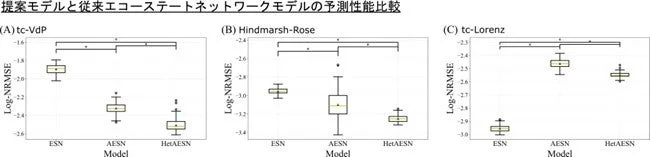
特にHRモデルでは、速い信号に対応するサブリザバーに高い入力スケール値が割り当てられており、HetAESNがタスクの時間と空間の特性にうまく適合していることが示唆されました。しかし、tc-Lorenzタスクでは、従来のESNを下回る結果となりました。
この性能の違いの理由を明らかにするため、「遅延容量(DC)」と「マルチスケールファジィエントロピー(MFE)」という分析手法を用いて、AIが過去の情報をどれだけ長く記憶できるか、そしてデータがどれだけ複雑かという点を詳しく調べました。
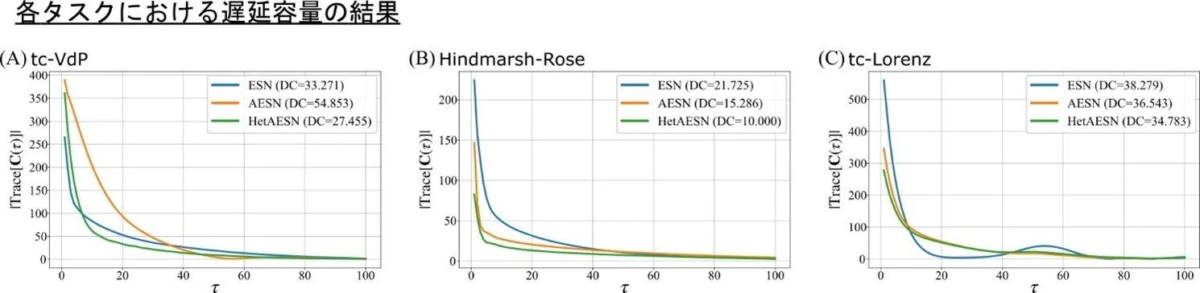
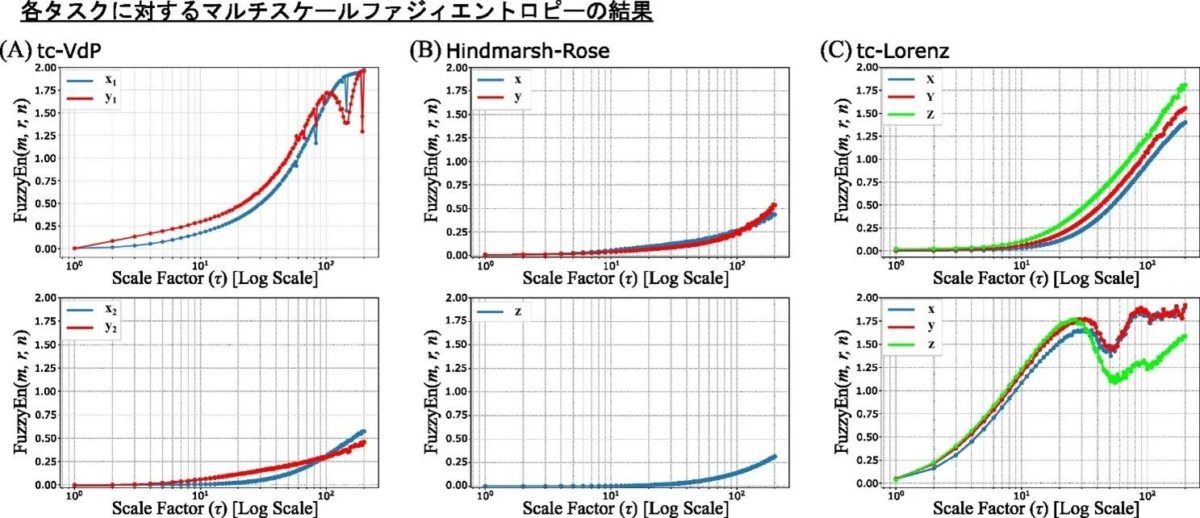
分析の結果、tc-Lorenzタスクのように次元数が比較的高く、かつデータの複雑性が高い場合、入力データを分割することで各サブリザバーのサイズが相対的に小さくなり、その限られた能力では複雑な信号を処理しきれなかったことが、性能低下の主な原因であると結論付けられました。このことから、「データを分割する構造的な利点」と「個々のAIが持つ表現力」の間にはバランスが重要であることが明らかになりました。
今後の展望
今回の研究で提案されたHetAESNは、高次元でマルチスケールな時系列データを効率的に処理する可能性を示しました。その有効性が「入力データの次元数」と「AIが記憶できる範囲内のデータの複雑性」のバランスに依存するという知見は、今後のAIモデル設計において重要な指針となるでしょう。
今後は、合成データだけでなく、生体信号解析やIoTセンサーデータなど、現実世界に存在する高次元かつマルチスケールなタスクへのHetAESNの適用と、その汎用性の検証が行われる予定です。また、tc-Lorenzタスクで示された「表現力不足」の課題を克服するため、AIの表現力を高める新しい仕組みの導入が今後の研究課題となります。
この研究成果は、2025年12月15日に、IEEE Accessにて発表されました。
原著論文情報
-
雑誌名: IEEE Access
-
論文題目: Heterogeneous Assembly Echo State Networks for High-Dimensional, Multiscale Time Series: Dynamic Analysis via Delay Capacity and Multiscale Fuzzy Entropy
-
著者: Sota Yoshida, Takahiro Iinuma, Sou Nobukawa, Eiji Watanabe, and Teijiro Isokawa
-
DOI: 10.1109/ACCESS.2025.3639721
用語説明
-
遅延容量(DC): AIが過去の入力情報をどれだけ長く保持できるか(記憶能力)を、タスクに依存しない形で数値化する指標です。
-
マルチスケールファジィエントロピー(MFE): 時系列データの不規則性や複雑さを、複数の異なる時間スケールで数値化する分析手法です。

