GMOインターネット株式会社は、AI開発を支える「GMO GPUクラウド」で、最新の「NVIDIA B300 GPU」と、これまで提供してきた「NVIDIA H200 GPU」の性能を詳しく調べた結果を公開しました。
「GMO GPUクラウド」は、AIを動かすための高性能なコンピューターの力を提供するサービスです。今回の検証は、生成AI(文章や画像を自動で作るAI)の開発から実際に使うまでの実用性や、計算の速さを評価するために行われました。
実施されたベンチマークの概要
AIの性能を測るために、以下の3種類のテスト(ベンチマーク)が実施されました。
- 大規模言語モデル(LLM)の学習ベンチマーク:AIが新しい知識を学ぶ「学習」の効率と速さを測ります。具体的には、LLMが目標の賢さに達するまでの時間を計りました。
- vLLM bench throughputによる推論ベンチマーク:AIが質問に答えるなどの「推論」の速さを測ります。1秒間にどれくらいの量の言葉(トークン)を生み出せるか、という処理能力を比較しました。
- HPL Benchmarkによるベンチマーク:科学技術計算など、非常に正確な計算が必要な場合の処理能力を測ります。スーパーコンピューターの性能評価にも使われる指標です。
これらのテストを通じて、「B300 GPU」と「H200 GPU」が、それぞれどのようなAIの作業に適しているかが検証されました。
ベンチマークテストの結果
今回の検証では、生成AIの作業において「B300 GPU」が「H200 GPU」と比べて、学習では約2倍、推論では約2.5倍の処理性能を発揮することが確認されました。しかし、HPL Benchmarkでは「B300 GPU」の性能は「H200 GPU」の約47分の1にとどまる結果となりました。
これは、「B300 GPU」が生成AIの作業に特化して高い性能を持つ一方で、非常に正確な計算が求められる科学技術計算などでは、「H200 GPU」が引き続き適していることを示唆しています。
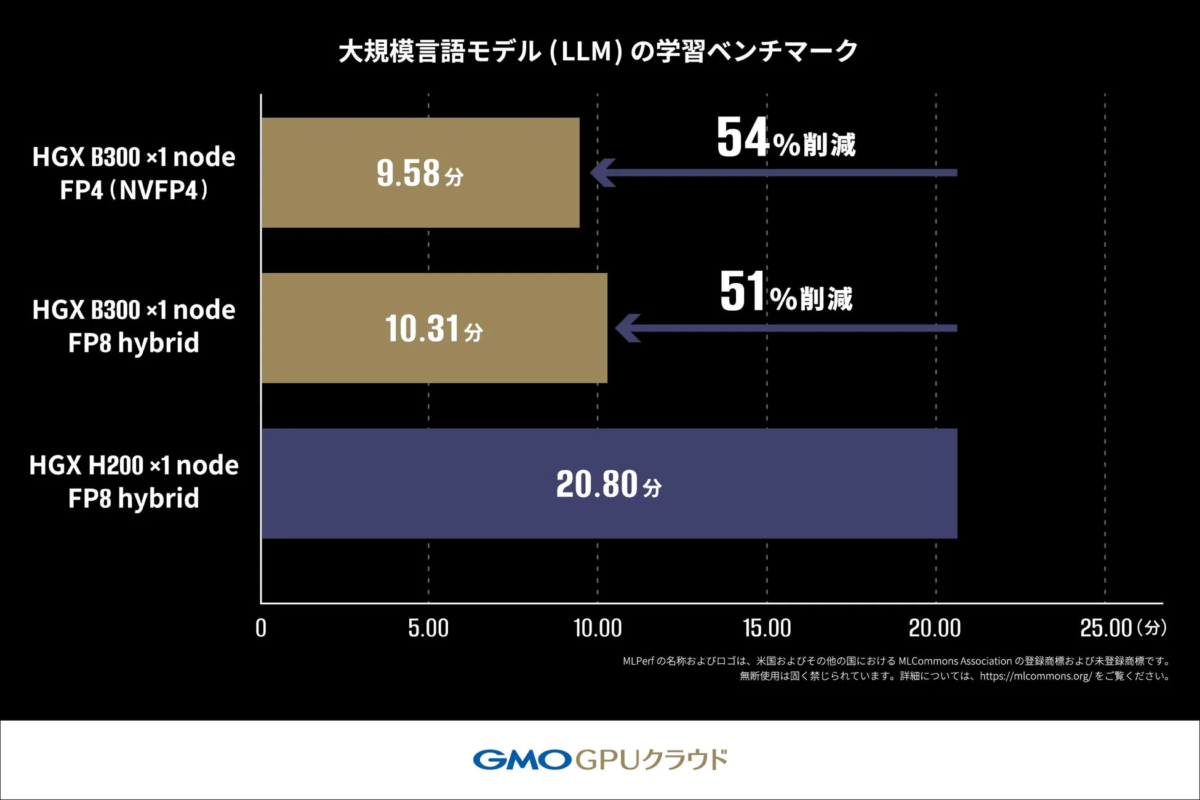
1. 大規模言語モデル(LLM)の学習ベンチマーク
このテストでは、Llama2 70Bという大規模言語モデルを使って、AIの学習にかかる時間を比較しました。AIの予測精度を示す「クロスエントロピー損失」という値が目標に達するまでの時間を測定しています。

結果として、「H200 GPU」を使った場合は20.80分かかった学習が、「B300 GPU」では10.31分で完了し、約2倍の速さで処理が進みました。
さらに、NVIDIAの新しい技術である「FP4(4ビット浮動小数点演算)」を使うと、より短い時間で学習が完了することが分かり、FP4が学習の高速化に役立つ可能性が示されました。
2. vLLM bench throughputによる推論ベンチマーク
このテストでは、Llama-3.1-405B-Instructというモデルを使って、AIが1秒間にどれくらいの言葉(トークン)を生み出せるかを比較しました。
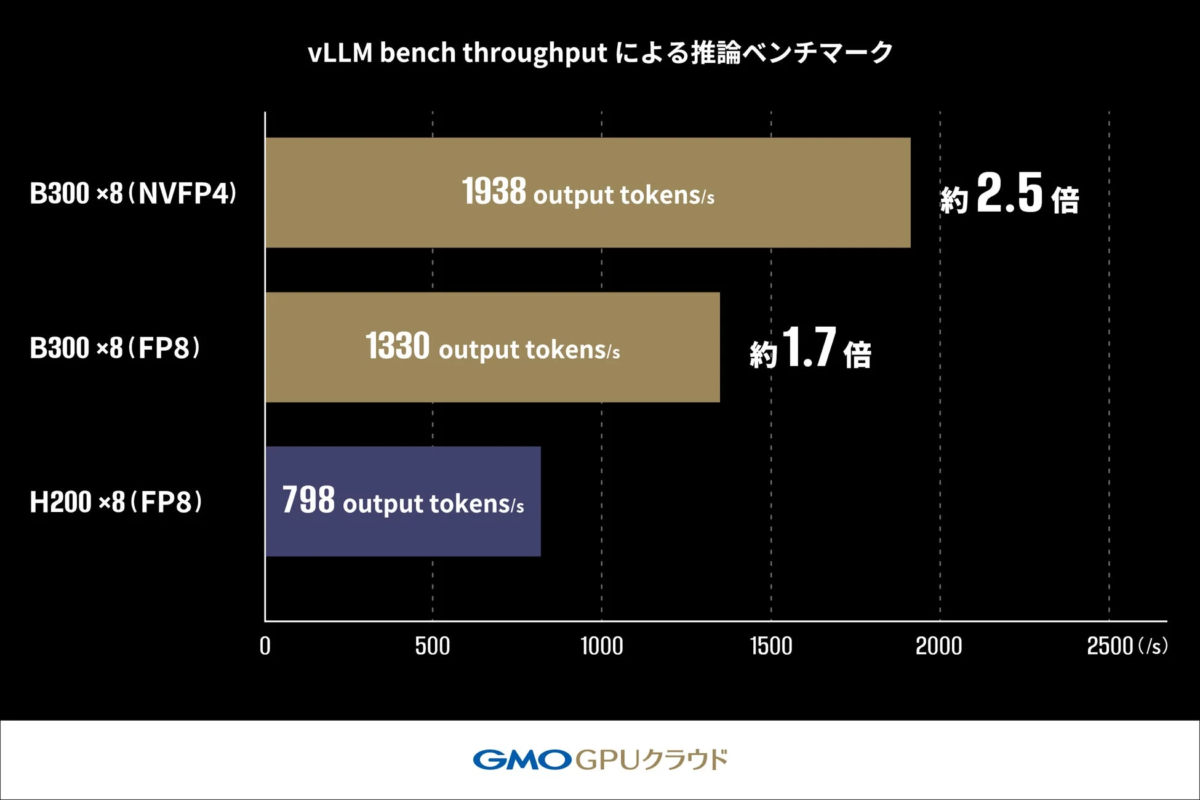
「H200 GPU」では1秒あたり798トークンだった処理能力が、「B300 GPU」では1330トークンまで向上し、約1.7倍の速度となりました。FP4を適用するとさらに性能が向上し、1938トークン/秒を達成。「H200 GPU」の約2.5倍の性能向上が確認されました。この結果は、FP4が大規模モデルの推論性能を高める有効な手段であることを示しています。
3. HPL Benchmarkによるベンチマーク
HPL Benchmarkは、非常に複雑な計算を正確に解く能力(LINPACK性能)を測るものです。1秒間に実行できる計算回数をGFLOPSという単位で表し、この値が高いほど高性能とされます。
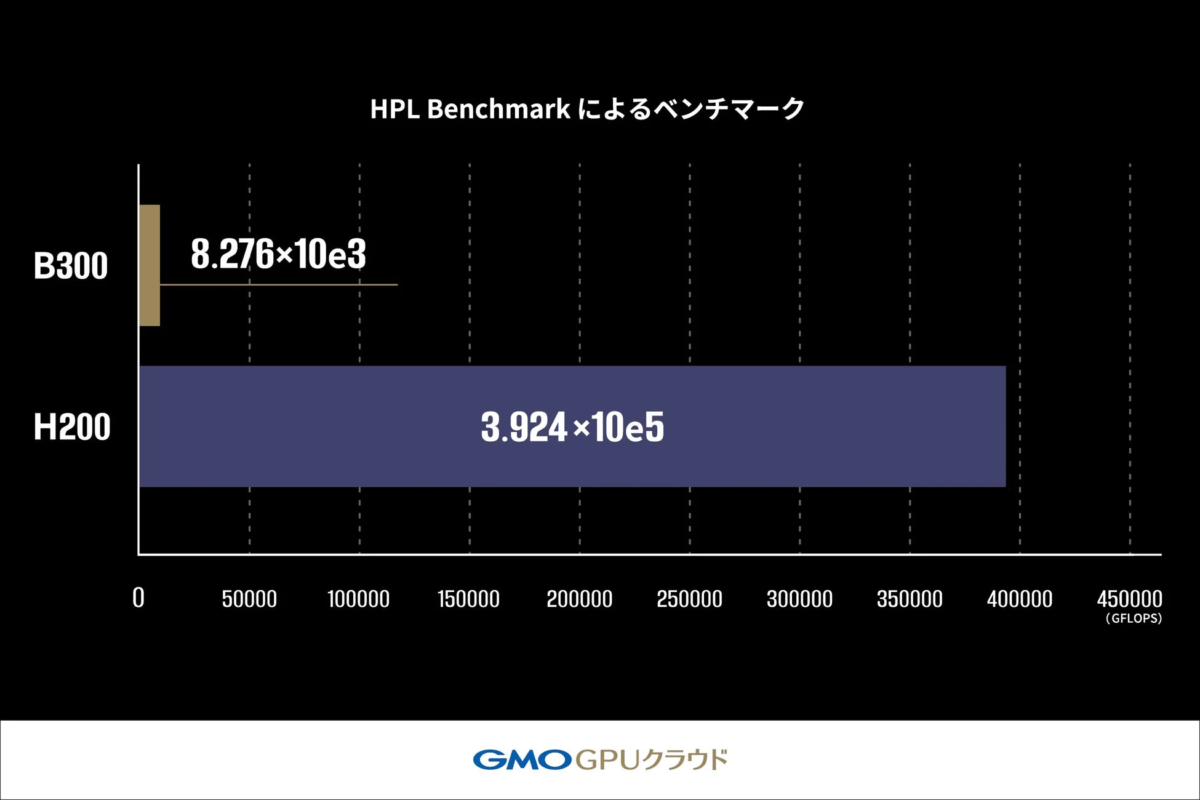
このテストでは、「B300 GPU」の性能は「H200 GPU」の約2.1%(約47分の1)という結果になりました。これは、「B300 GPU」が生成AIの作業に特化して作られているためだと考えられます。そのため、気象予測や創薬研究など、計算結果の正確性が厳しく求められる科学技術計算の分野では、「H200 GPU」が引き続き適していると考えられます。
実施環境
| H200 | B300 | |
|---|---|---|
| サーバモデル | DELL PowerEdge XE9680 | DELL PowerEdge XE9780 |
| CPU | 第4世代インテル® Xeon® スケーラブル・プロセッサー・ファミリー | 第6世代インテル® Xeon® スケーラブル・プロセッサー・ファミリー |
| ディスク構成 | NVMe 7.68TB x4 | NVMe 3.5TB x8 |
| GPU | NVIDIA HGX H200 | NVIDIA HGX B300 |
GMOインターネットからのコメント
GMOインターネットのインフラ・運用本部 プロジェクト統括チーム エグゼクティブリードである佐藤嘉昌氏は、今回のベンチマーク結果は特定の環境下での検証結果ではあるものの、「B300 GPU」と「H200 GPU」の性能の違いを示す参考情報になると述べています。
また、「GMO GPUクラウド」は、顧客のAI開発の目的や使い方に合わせて、より効率的に計算資源を活用できるよう、技術的なサポートを続けていく意向を示しています。このような検証結果の提供を通じて、顧客が最適なGPUクラウドサービスを選べるよう支援し、日本のAI産業の発展に貢献していく方針です。
今後の展開
GMOインターネットは、今後も「GMO GPUクラウド」を通じて、生成AI分野に取り組む企業や研究機関に、用途に応じた最適なGPUクラウドサービスを提供していきます。
今回の検証結果を踏まえ、生成AIの学習や推論に強い「B300 GPU」と、高精度な数値計算に適した「H200 GPU」を、顧客のニーズに合わせて柔軟に組み合わせた提案を行う予定です。単にGPUを提供するだけでなく、開発目的や利用用途に合わせた環境のカスタマイズから、運用の最適化まで、技術面とコスト面の両方で支援することで、開発期間の短縮とコスト削減に貢献し、国内AI産業の発展を促進していくとしています。
「GMO GPUクラウド」について
「GMO GPUクラウド」は、NVIDIA H200 Tensor コアGPUを搭載し、国内初の高速ネットワーク NVIDIA Spectrum-X と高速ストレージを実装したサービスです。2024年11月には世界のスーパーコンピュータ性能ランキング「TOP500」で世界第37位・国内第6位にランクインし、商用クラウドサービスとしては国内最速クラスの計算基盤を提供しています。
さらに、2025年6月には電力効率を競う世界ランキング「Green500」で世界第34位・国内第1位を獲得し、高性能と省電力性の両立が国際的に評価されました。2025年12月にはNVIDIAの次世代GPU「NVIDIA Blackwell Ultra GPU」を搭載した「NVIDIA HGX B300」のクラウドサービス提供も国内最速クラスで開始しています。
サービス詳細については、GMO GPUクラウドをご覧ください。
関連情報

